|
I join the City University of Hong Kong (DG) as an Assistant Professor from 2025 Spring. I was a PostDoc in LAMP group at Computer Vision Center (CVC), UAB. Before that I graduate as a PhD under the supervision of Joost van de Weijer in 2022. I received my master degree in image processing from Jilin University in 2017 and the bachelor degree from Jilin University in 2014. I have worked on a wide variety of projects including Diffusion Models, Continual Learning and Vision Transformers. Now I am mainly working on multiple projects on diffusion models and advising several PhD students on related topics. Email / Google Scholar / LinkedIn / Twitter / Github / Awesome Diffusion |

|
|
2025-09: 3 paper accepted by NeurIPS 2025. 2025-03: 2 paper accepted by CVPR 2025. 2025-01: 2 paper accepted by ICLR 2025, including one Spotlight paper 1Prompt1Story (<5%). 2025-01: We are looking for PostDocs to join LAMP group working on Diffusion Models. 2024-10: 1 paper accepted by IEEE TGRS 2024-10: 1 paper accepted by WACV 2025 2024-09: I will serve as an on-site organizer for the first AVGenL workshop in ECCV 2024. 2024-09: 1 paper accepted by NeurIPS 2024 2024-08: Give a live presentation online on the course.zhidx.com platform 2024-07: 2 papers accepted in ECCV, 1 paper in IEEE Transactions on Intelligent Vehicles, 1 paper in ECAI 2024-03: 1 paper accepted in CVPR 2024 AI4CC workshop, 1 paper in ICME 2024 2024-01: 1 paper accepted by Knowledge-Based Systems 2023-10: 1 paper accepted in WACV 2024 2023-09: 1 paper accepted in NeurIPS 2023 2023-04: 1 paper accepted in ICCV 2023 VCL workshop |
|
|
|
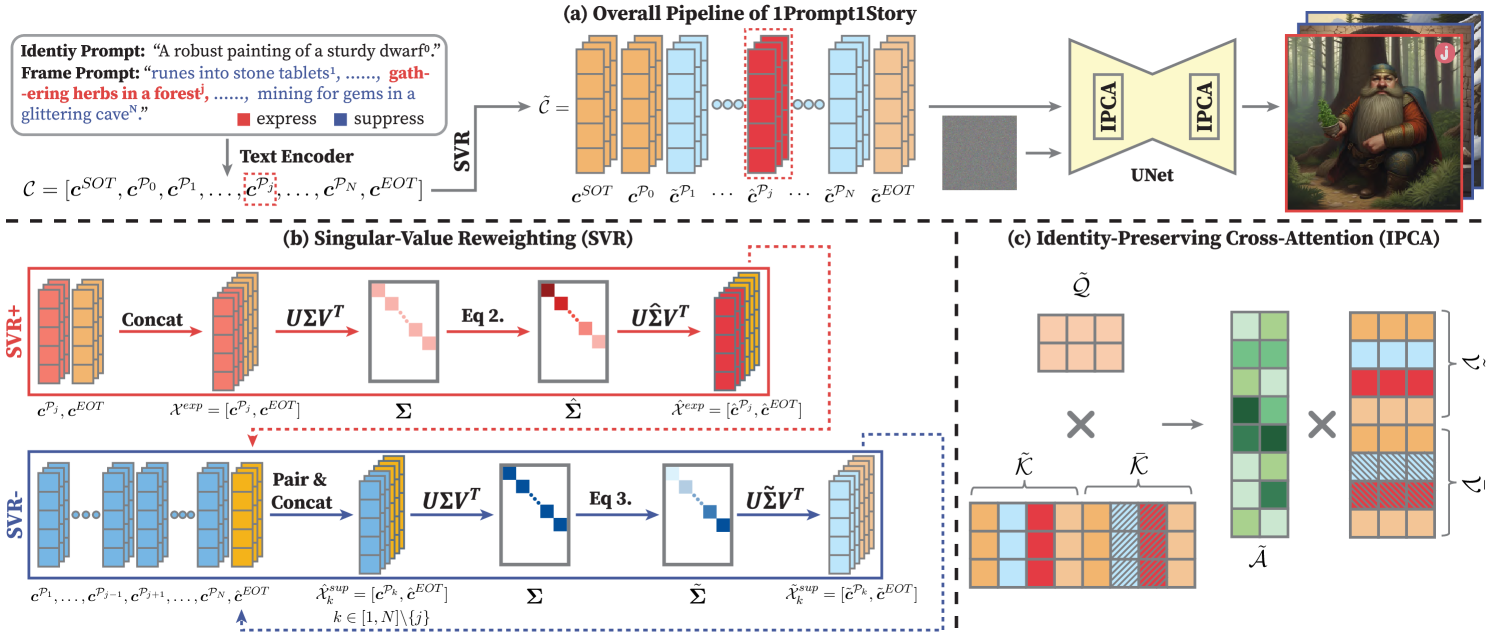
Tao Liu. Kai Wang*. Senmao Li. Joost van de Weijer. Fahad Khan. Shiqi Yang. Yaxing Wang. Jian Yang. Ming-Ming Cheng. ICLR Spotlight, 2025 project page / arXiv We propose a training-free approach named 1Prompt1Story for consistent text-to-image generations with a single concatenated prompt. Our method is built on the inherent context consistency propoerty of language models. |
|
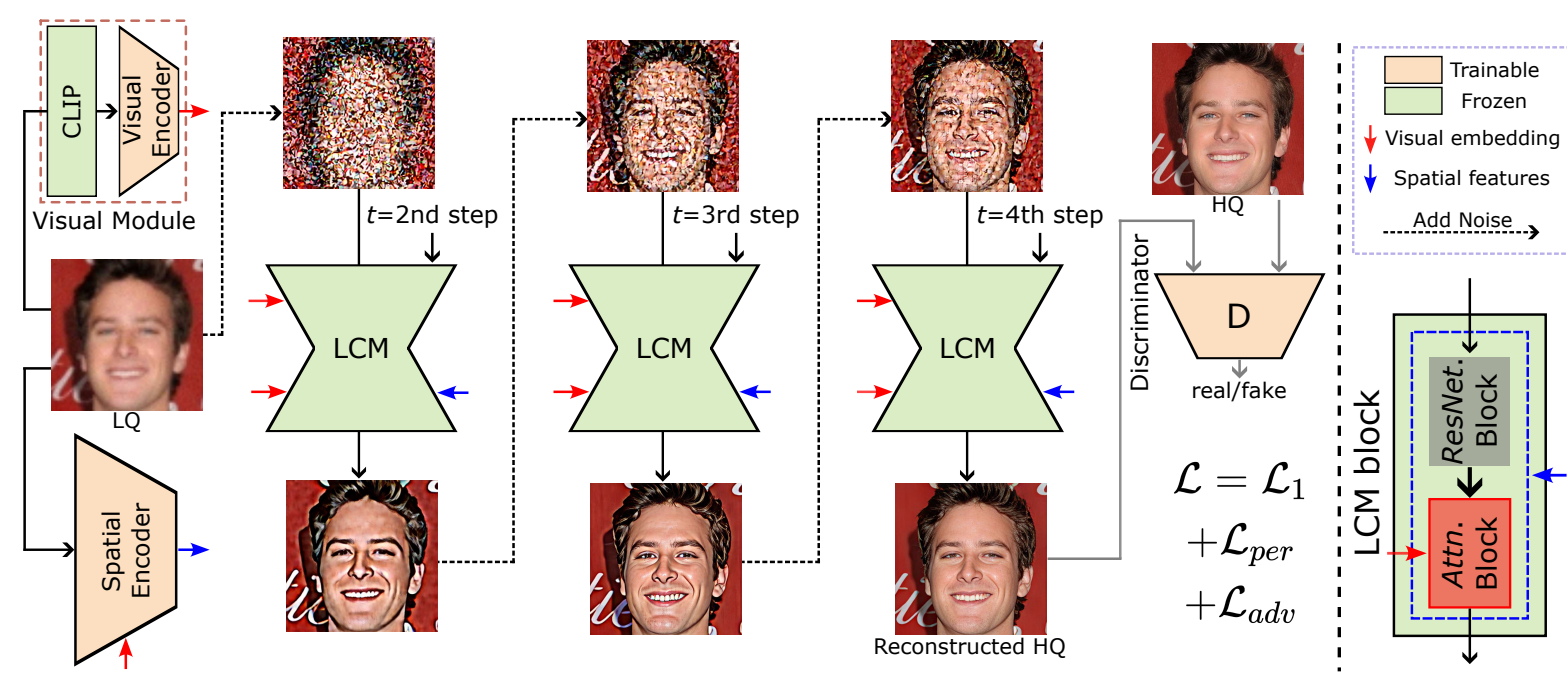
Senmao Li. Kai Wang*. Joost van de Weijer. Fahad Khan. Chunle Guo. Shiqi Yang. Yaxing Wang. Jian Yang. Ming-Ming Cheng. ICLR, 2025 project page / arXiv By regarding the lq image as intermediate state of the LCM, this paper propose the method InterLCM, along with extra conditions as visual embeddings and spatial embeddings, for efficient blind face restoration. |
|
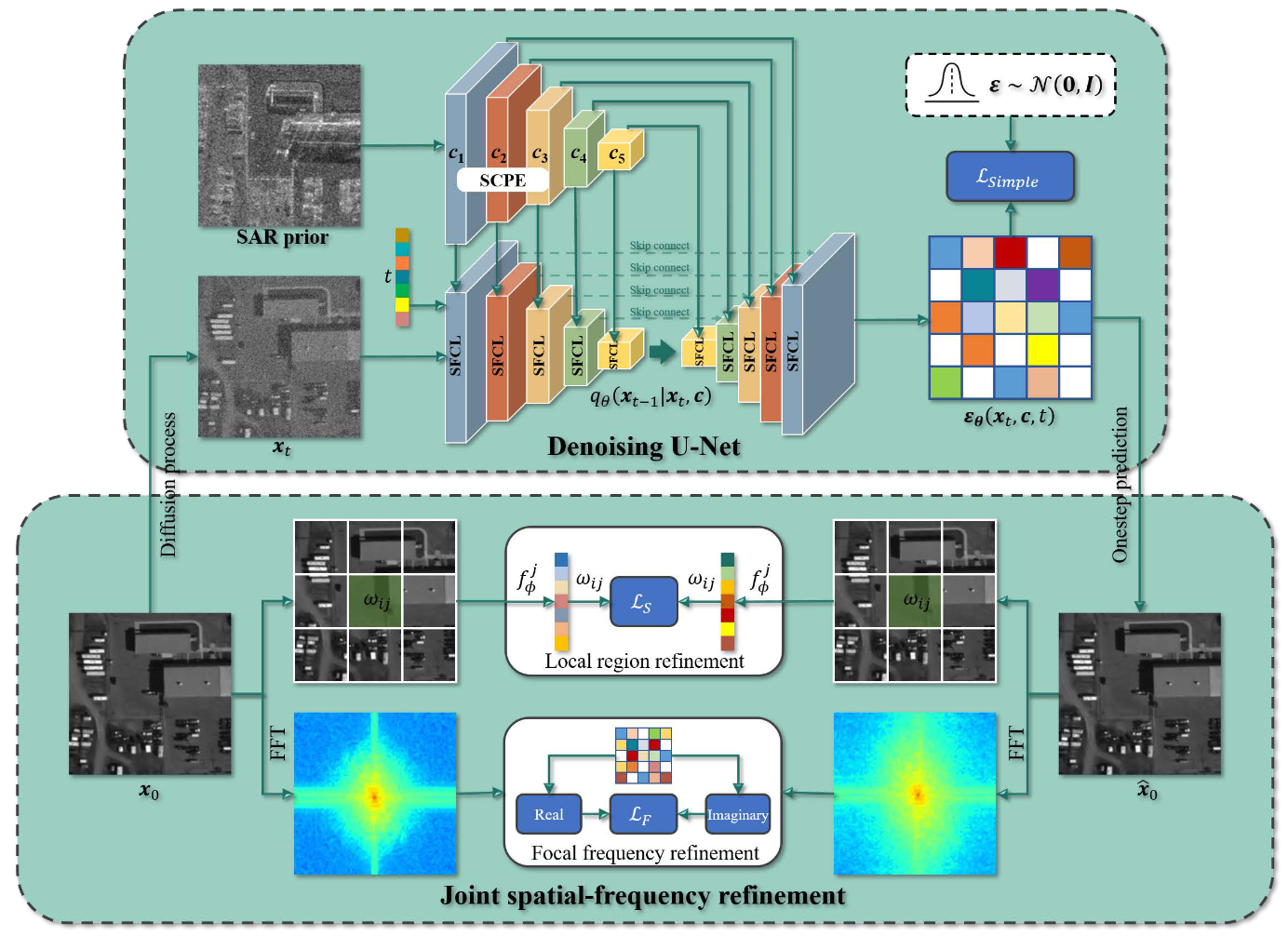
Jiang Qin. Kai Wang*. Bin Zou. Lamei Zhang. Joost van de Weijer. IEEE TGRS, 2025 project page / arXiv In this paper, we propose an augmented conditional denoising diffusion probabilistic model with spatial-frequency refinement (SFDiff) for high-fidelity S2O image translation. |
|
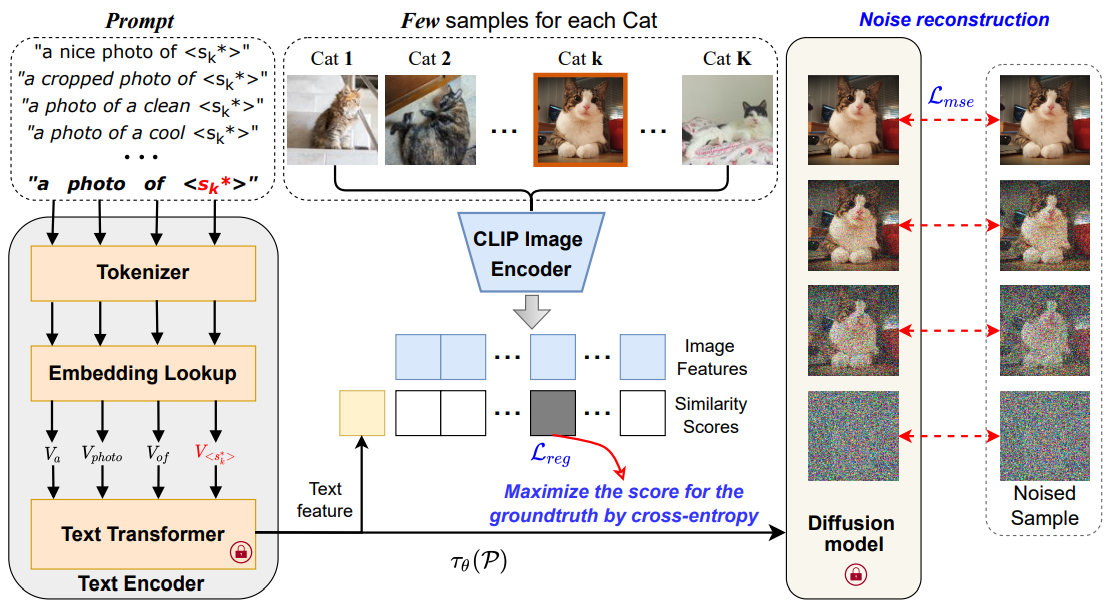
Kai Wang*. Fei Yang. Bogdan Raducanu. Joost van de Weijer. WACV, 2025 project page / arXiv We propose Multi-Class textual inversion, which includes a discriminative regularization term for the token updating process. Using this technique, our method MC-TI achieves stronger Semantic-Agnostic Classification while preserving the generation capability of these modifier tokens given only few samples per category. |
|
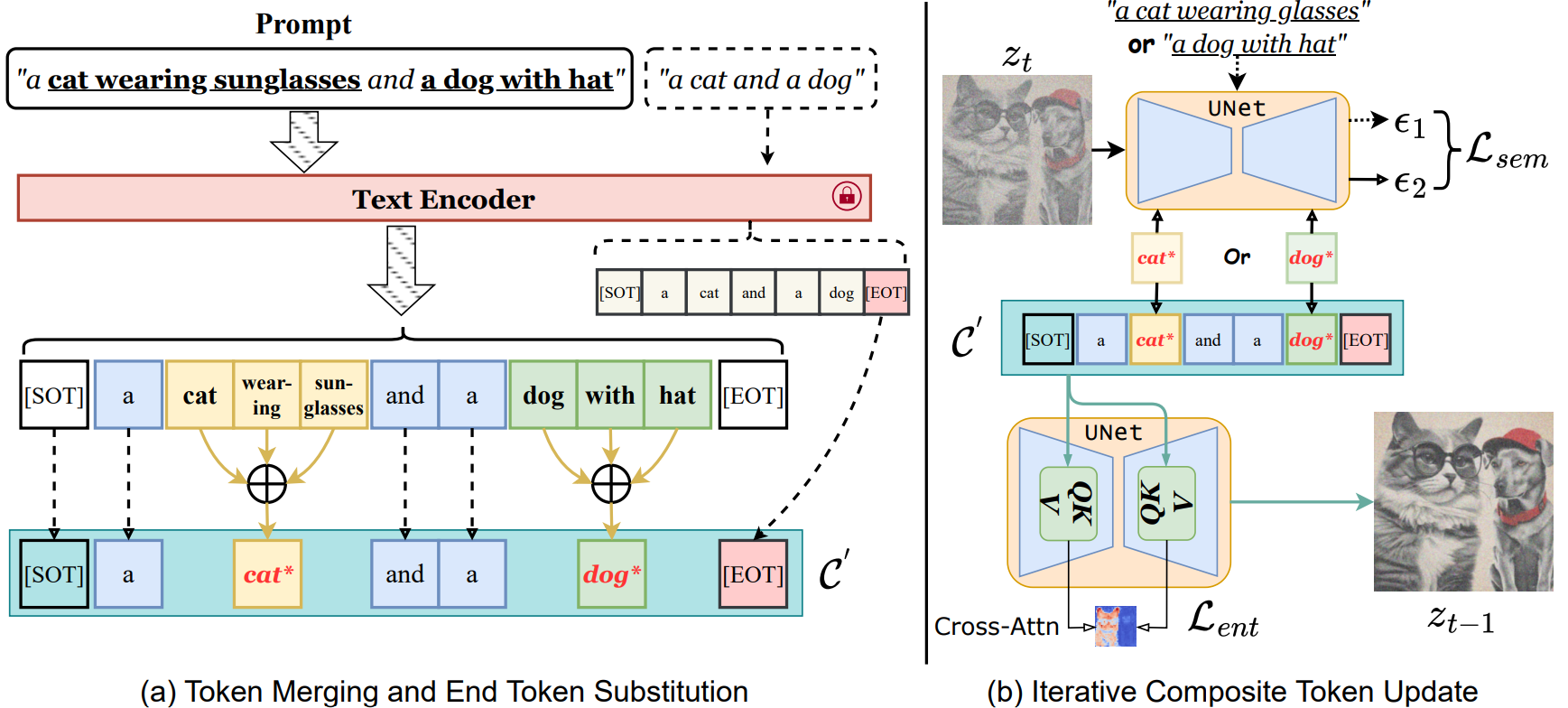
Taihang Hu. Linxuan Li. Joost van de Weijer. Hongcheng Gao. Fahad Khan. Jian Yang. Ming-Ming Cheng. Kai Wang*. Yaxing Wang. NeurIPS, 2024 project page / arXiv In this paper, we define semantic binding as the task of associating a given object with its attribute, termed attribute binding, or linking it to other related sub-objects, referred to as object binding. We introduce a novel method called Token Merging (ToMe), which enhances semantic binding by aggregating relevant tokens into a single composite token. This ensures that the object, its attributes and sub-objects all share the same cross-attention map. |

|
Muhammad Atif Butt. Kai Wang*. Javier Vázquez-Corral. Joost van de Weijer. ECCV, 2024 project page / arXiv We propose to generate a series of geometric shapes with target colors to disentangle (or peel off ) the target colors from the shapes. By jointly learning on multiple color-shape images, we found that the method can successfully disentangle the color and shape concepts. |
|
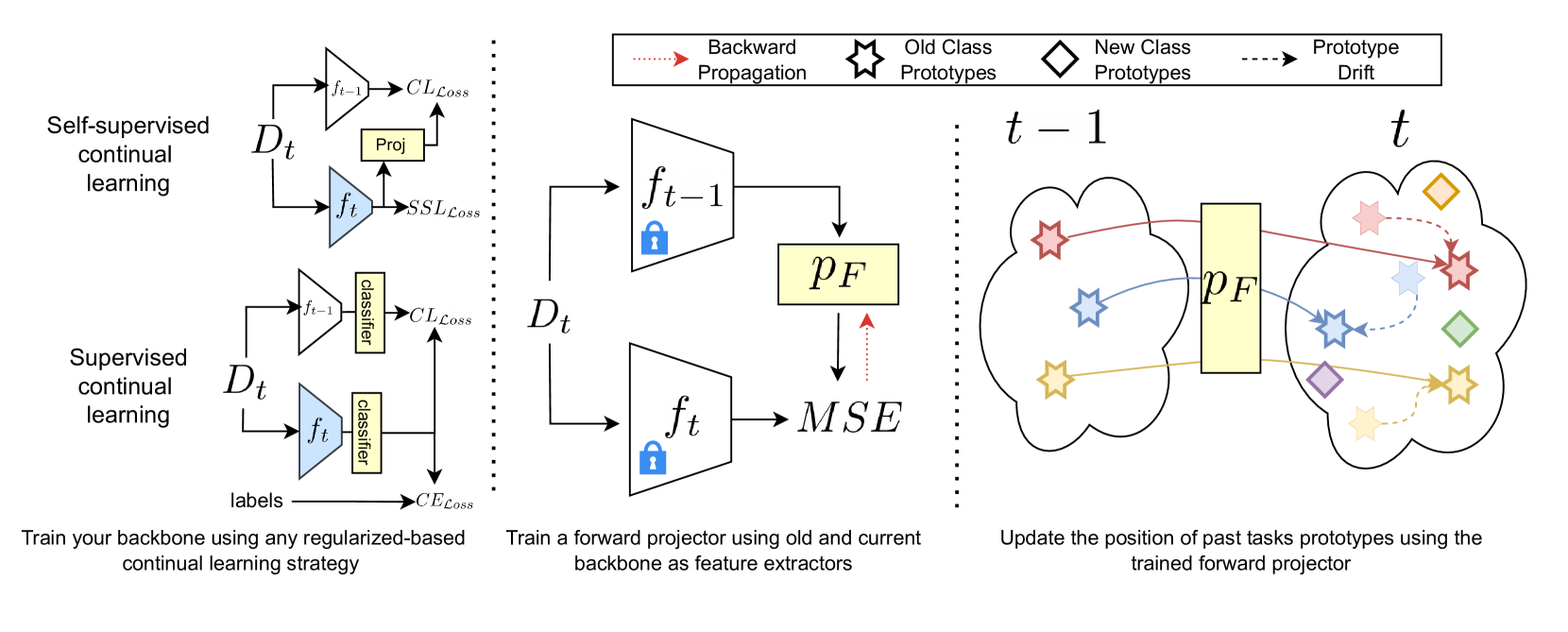
Alex Gomez-Villa. Dipam Goswami. Kai Wang*. Andrew D. Bagdanov. Bartlomiej Twardowski. Joost van de Weijer. ECCV, 2024 project page / arXiv We propose Learnable Drift Compensation (LDC), which can effectively mitigate drift in any moving backbone, whether supervised or unsupervised. LDC is fast and straightforward to integrate on top of existing continual learning approaches. Furthermore, we showcase how LDC can be applied in combination with self-supervised CL methods, resulting in the first exemplar-free semi-supervised continual learning approach. |
|
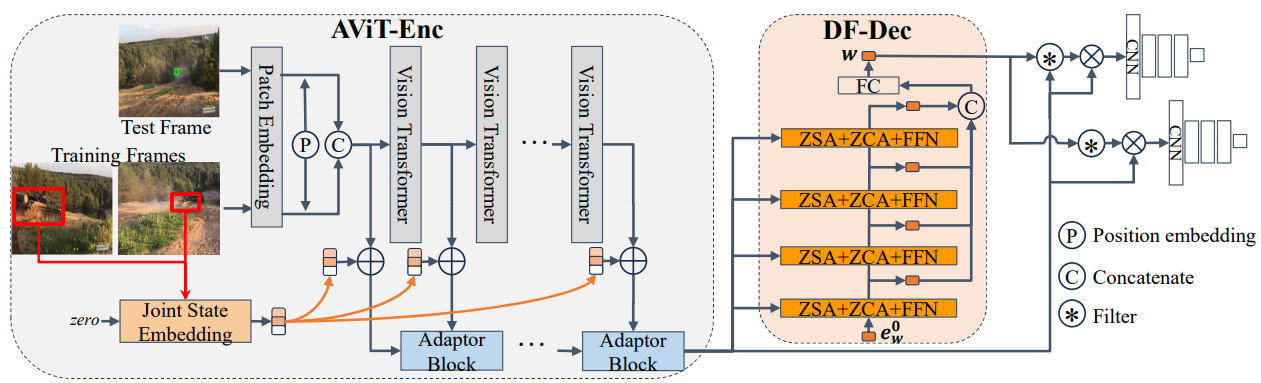
Chuanming Tang. Kai Wang*. Joost van de Weijer. Jianlin Zhang, Yongmei Huang. IEEE Transactions on Intelligent Vehicles, 2024 arXiv To tackle the inferior effectiveness of the vanilla ViT, we propose an Adaptive ViT Model Prediction tracker (AViTMP) to bridge the gap between single-branch network and discriminative models. |
|
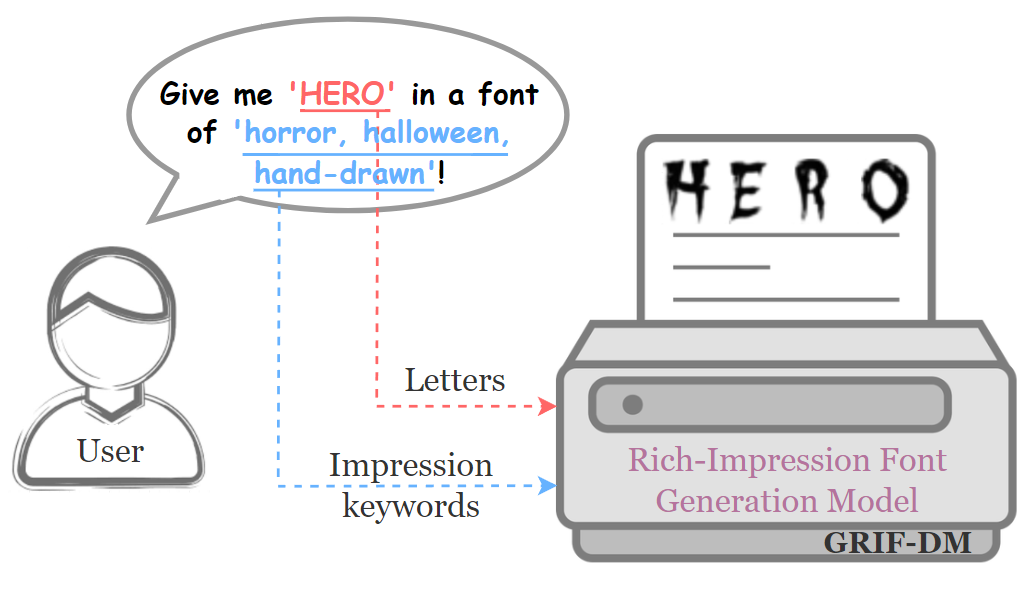
Lei Kang. Fei Yang. Kai Wang*. Mohamed Ali Souibgui. Lluis Gomez. Alicia Fornés. Ernest Valveny. Dimosthenis Karatzas. ECAI, 2024 arXiv TIn this paper, we introduce a diffusion-based method, termed GRIF-DM, to generate fonts that vividly embody specific impressions, utilizing an input consisting of a single letter and a set of descriptive impression keywords. The core innovation of GRIF-DM lies in the development of dual cross-attention modules, which process the characteristics of the letters and impression keywords independently but synergistically, ensuring effective integration of both types of information. |

|
Chuanming Tang. Kai Wang*. Fei Yang. Joost van de Weijer. CVPR AI4CC workshop, 2024 project page / arXiv We address the cross-attention leakage problem in Text-to-Image diffusion model inversions by introducing the localization priors. |

|
Tao Wu, Kai Wang*. Chuanming Tang. Jianlin Zhang. Knowledge-Based Systems, 2024 Journal We propose a novel diffusion-based network (DBN) for unsupervised landmark detection, which leverages the generation ability of the diffusion models to detect the landmark locations. |

|
Chuanming Tang. Kai Wang*. Joost van de Weijer. ICME, 2024 & NeurIPS 2023 workshop on Diffusion Models project page / arXiv We develop an iterative inversion (IterInv) technique for the pixel level T2I models and verify IterInv with the open-source DeepFloyd-IF model. |
|
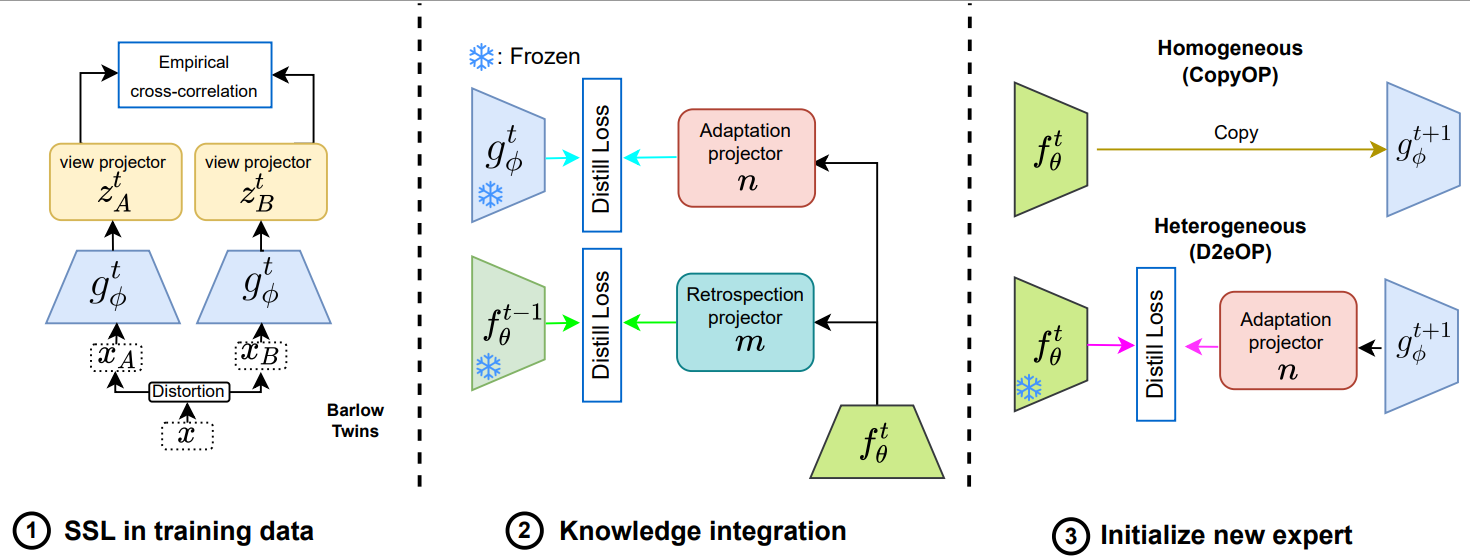
Alex Gomez-Villa. Bartlomiej Twardowski. Kai Wang*. Joost van de Weijer. WACV, 2024 project page / arXiv In this continual learning paper, we propose to train an expert network that is relieved of the duty of keeping the previous knowledge and can focus on performing optimally on the new tasks (optimizing plasticity). |

|
Kai Wang*. Fei Yang. Shiqi Yang. Muhammad Atif Butt. Joost van de Weijer. NeurIPS, 2023 project page / arXiv In this paper, we propose Dynamic Prompt Learning (DPL) to force cross-attention maps to focus on correct noun words in the text prompt. By updating the dynamic tokens for nouns in the textual input with the proposed leakage repairment losses, we achieve fine-grained image editing over particular objects while preventing undesired changes to other image regions. |
|
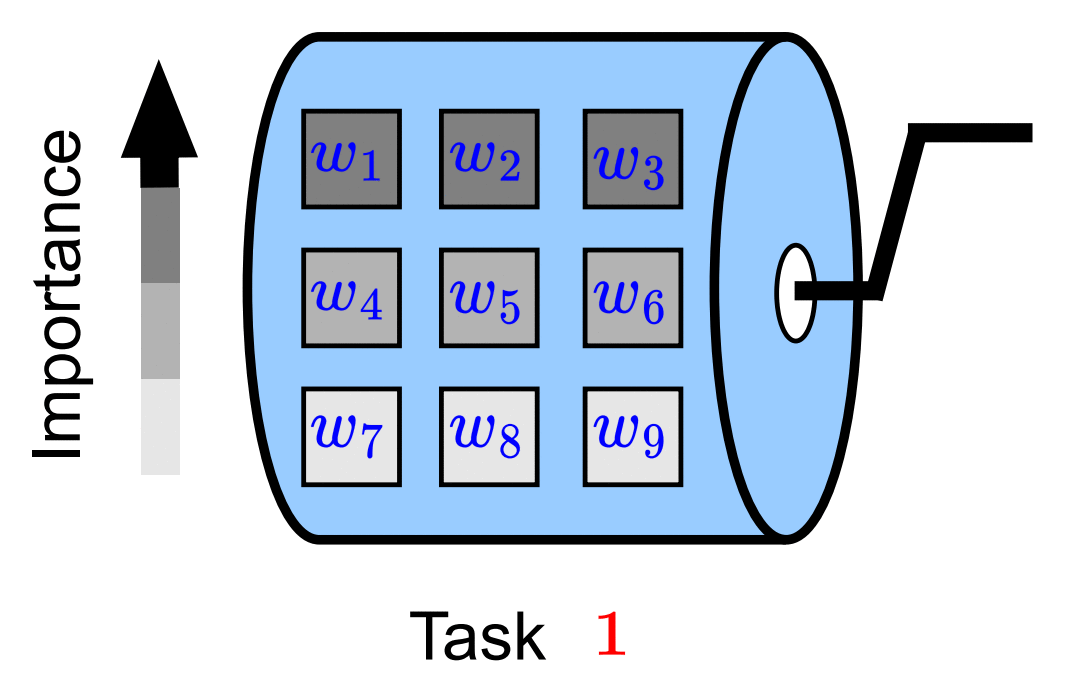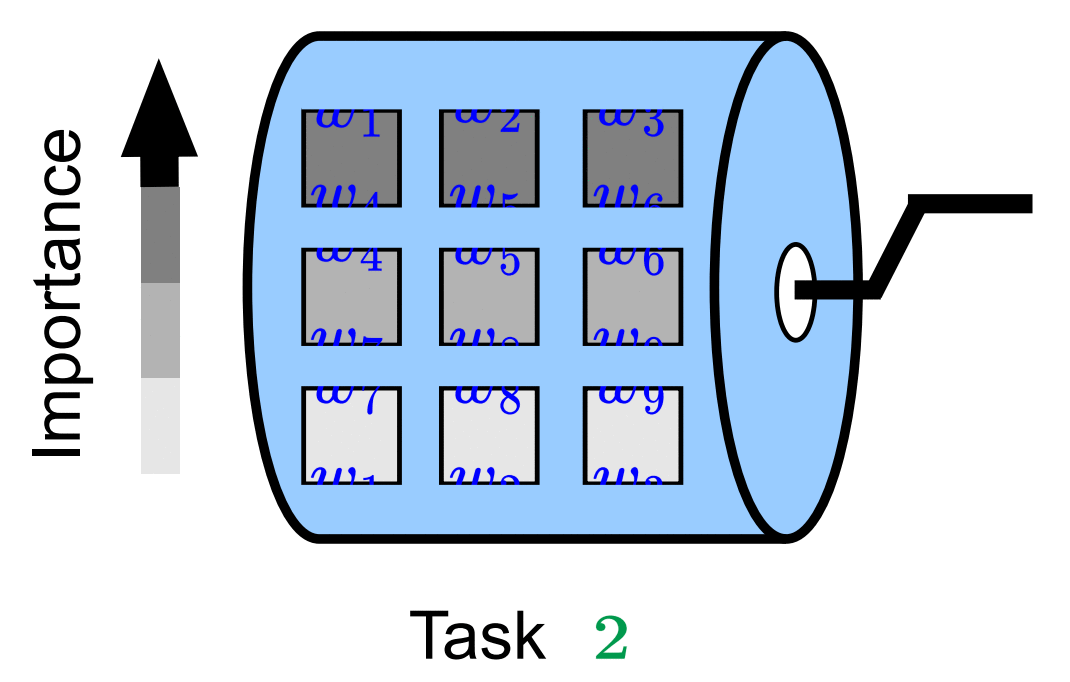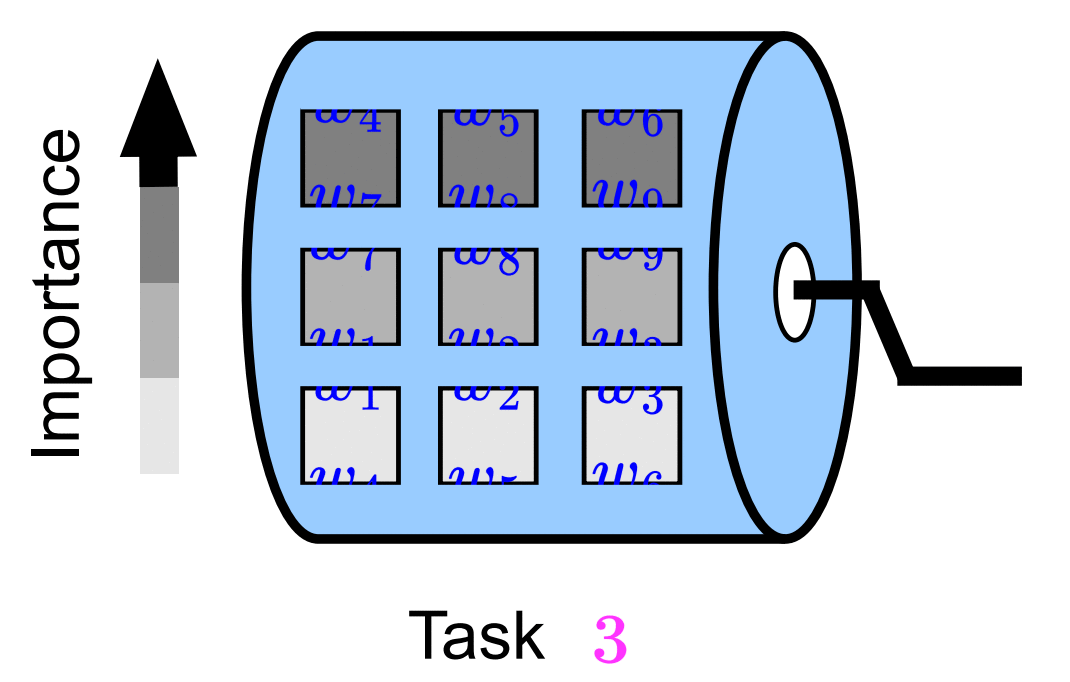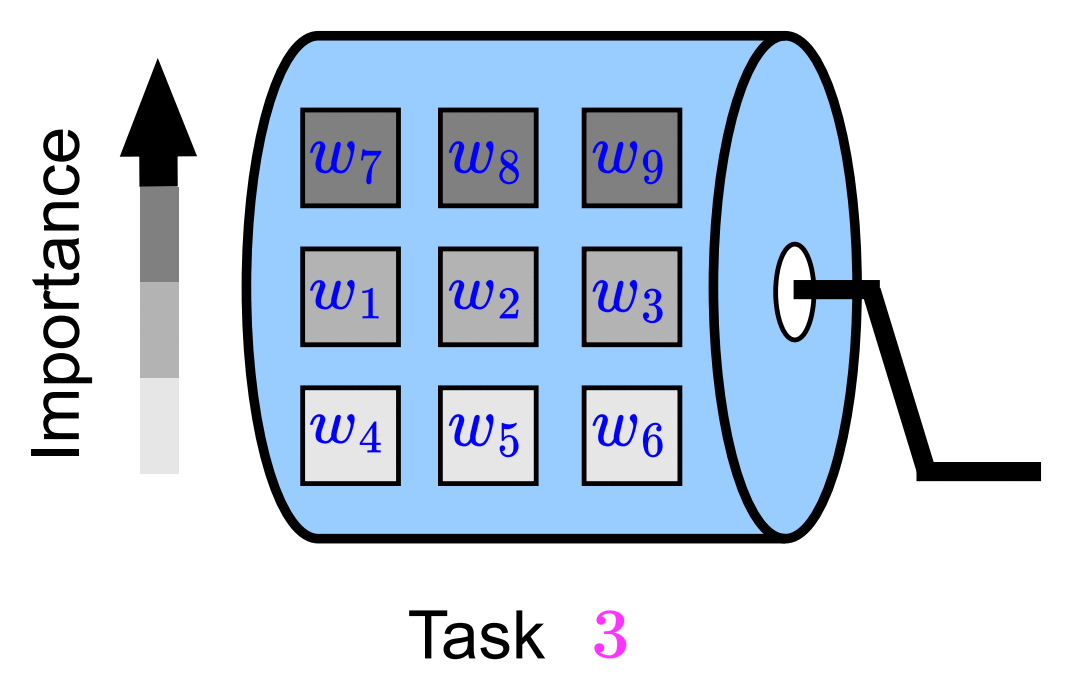
Fei Yang. Kai Wang*. Joost van de Weijer. ICCV VCL workshop, 2023 project page / arXiv In this paper, we propose ScrollNet as a scrolling neural network for continual learning. ScrollNet can be seen as a dynamic network that assigns the ranking of weight importance for each task before data exposure, thus achieving a more favorable stability-plasticity tradeoff during sequential task learning by reassigning this ranking for different tasks. |
|
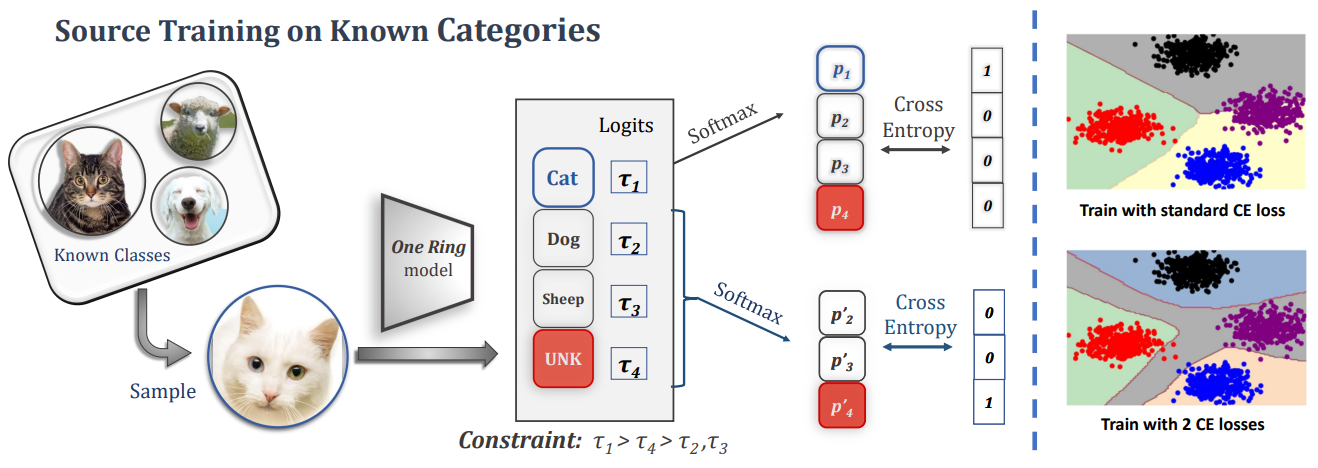
Shiqi Yang. Yaxing Wang. Kai Wang*. Shangling Jui, Joost van de Weijer. Under Review, 2023 project page / arXiv In this paper, we investigate Source-free Open-partial Domain Adaptation (SF-OPDA), which addresses the situation where there exist both domain and category shifts between source and target domains. |
|
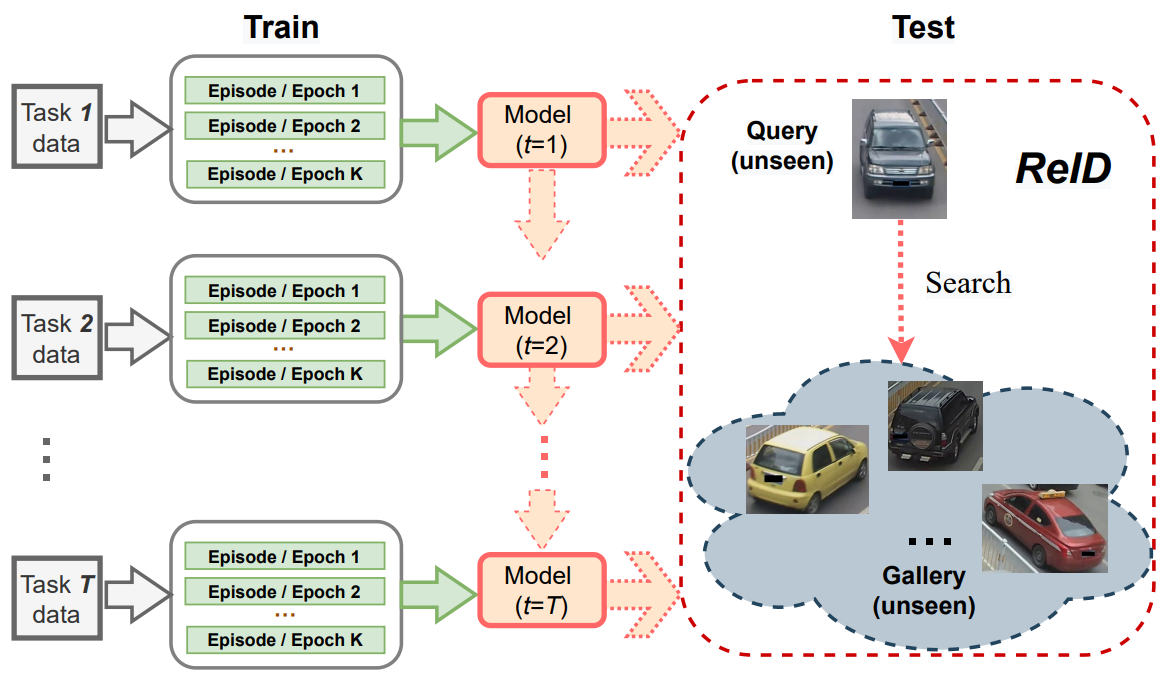
Kai Wang*. Chenshen Wu. Andrew D. Bagdanov. Xialei Liu. Shiqi Yang. Joost van de Weijer. BMVC, 2022 project page / arXiv To address the incremental Person ReID problem, we apply continual meta metric learning to lifelong object re-identification. To prevent forgetting of previous tasks, we use knowledge distillation and explore the roles of positive and negative pairs. Based on our observation that the distillation and metric losses are antagonistic, we propose to remove positive pairs from distillation to robustify model updates. |

|
Kai Wang*. Fei Yang. Joost van de Weijer. BMVC, 2022 project page / arXiv In this paper, we study knowledge distillation of self-supervised vision transformers (ViT-SSKD). We show that directly distilling information from the crucial attention mechanism from teacher to student can significantly narrow the performance gap between both. . |

|
Shiqi Yang. Kai Wang*. Yaxing Wang. Shangling Rui, Joost van de Weijer. NeurIPS (Spotlight), 2022 project page / arXiv We propose a simple but effective source-free domain adaptation (SFDA) method. Treating SFDA as an unsupervised clustering problem and following the intuition that local neighbors in feature space should have more similar predictions than other features, we propose to optimize an objective of prediction consistency. This objective encourages local neighborhood features in feature space to have similar predictions while features farther away in feature space have dissimilar predictions, leading to efficient feature clustering and cluster assignment simultaneously. |
|
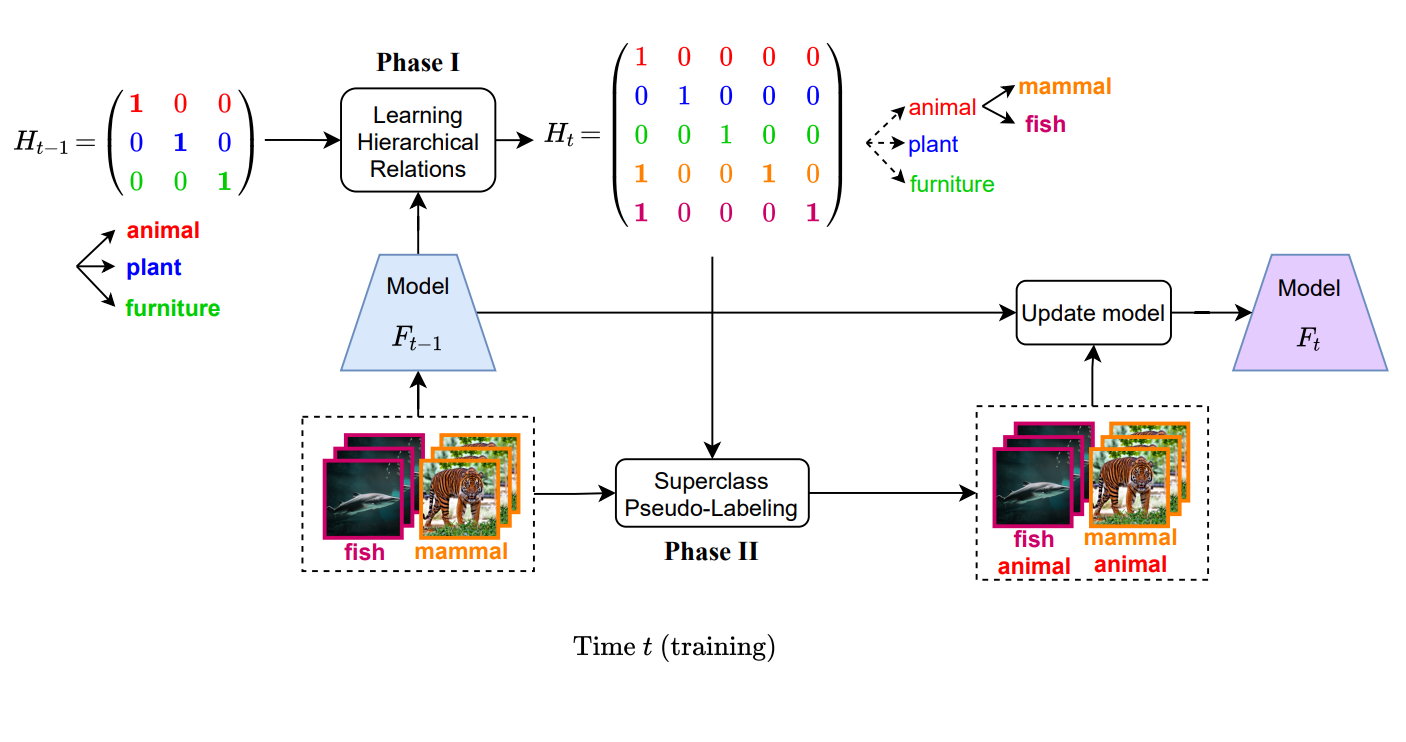
Kai Wang*. Xialei Liu. Luis Herranz, Joost van de Weijer. BMVC, 2021 project page / arXiv Current incremental learning methods lack the ability to build a concept hierarchy by associating new concepts to old ones. A more realistic setting tackling this problem is referred to as Incremental Implicitly-Refined Classification (IIRC), which simulates the recognition process from coarse-grained categories to fine-grained categories. To overcome forgetting in this benchmark, we propose Hierarchy-Consistency Verification (HCV) as an enhancement to existing continual learning methods. |
|
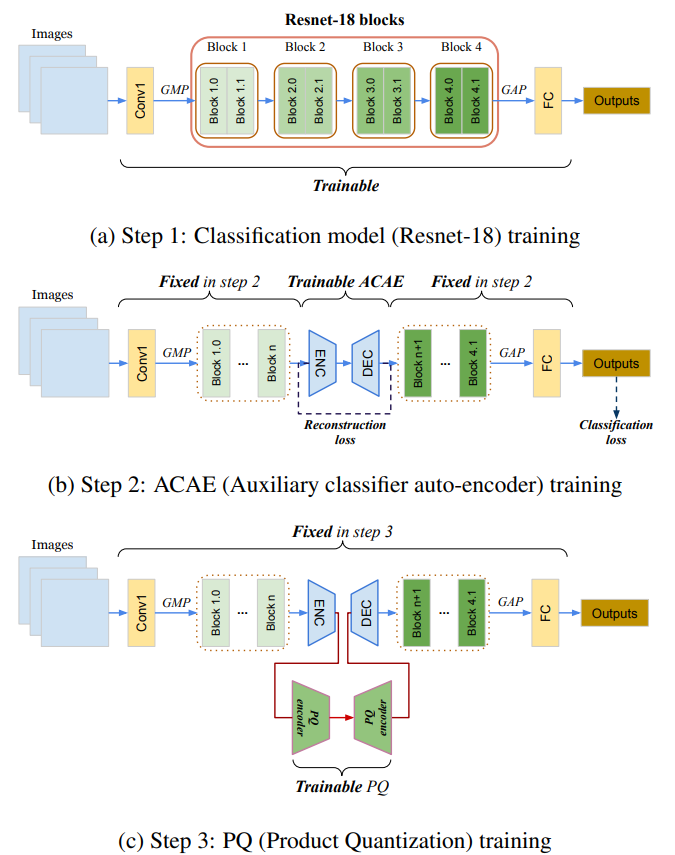
Kai Wang*. Luis Herranz, Joost van de Weijer. Pattern Recognition Letters, 2021 arXiv We propose an auxiliary classifier auto-encoder (ACAE) module for feature replay at intermediate layers with high compression rates. The reduced memory footprint per image allows us to save more exemplars for replay. |

|
Shiqi Yang. Kai Wang*. Luis Herranz, Joost van de Weijer. IEEE Signal Processing Letters, 2021 arXiv In this paper, we show that common ZSL backbones (without explicit attention nor part detection) can implicitly localize attributes, yet this property is not exploited. |

|
Lu Yu. Bartlomiej Twardowski. Xialei Liu. Luis Herranz, Kai Wang*. Yongmei Cheng, Shangling Rui, Joost van de Weijer. CVPR, 2020 project page / arXiv Embedding networks have the advantage that new classes can be naturally included into the network without adding new weights. Therefore, we study incremental learning for embedding networks. In addition, we propose a new method to estimate the drift, called semantic drift, of features and compensate for it without the need of any exemplars. We approximate the drift of previous tasks based on the drift that is experienced by current task data. |
|
|
|
|
Postdoctoral Researcher Supervised by Prof. Joost van de Weijer 2022-2024 |
|
|
Ph.D. student Supervised by Prof. Joost van de Weijer 2017-2022 |
|
|
Undergraduate student and Master student 2010-2017 |